موتورهای جستجو جهت بررسی کردن صفحات وب از رباتهای جستجوگر استفاده میکنند این رباتها صفحات وب را بررسی کرده و اطلاعات موردنظرشان را جمعآوری میکنند.

robot.txt یک فایل متنی است که توسط آن وب مسترها، ربات های جستجو را راهنمایی می کنند که چگونه وب سایت آنها را پیمایش و ایندکس کنند. در عمل فایل های robot.txt نشان می دهند که یک ربات موتور جستجو می تواند یا نمی تواند بخشی از وب سایت شما را پیمایش یا ایندکس نماید.
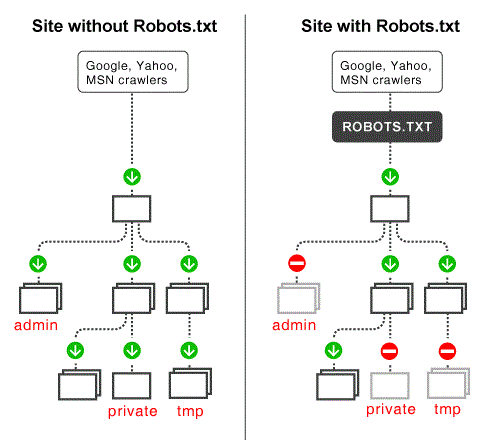
ربات های موتور های جستجو وقتی وارد وب سایت شما می شوند ابتدا این فایل را بررسی می کنند تا بدانند اجازه پیمایش چه بخش هایی از سایت شما را دارند. بدون این فایل ربات های موتور جستجو اجازه دارند تمامی قسمت های وب سایت شما را پیمایش و ایندکس کنند.
نکته: این فایل میبایست در root وب سایت شما باشد و آدرس زیر در دسترس باشد:
yourDomain.com/robots.txt
فرمت پایه:
User-agent: [user-agent name]
Disallow: [URL string not to be crawled]
این دو خط در کنار هم یک فابل robots.txt کامل را تشکیل می دهند، گرچه یک فایل می تواند محتوی چندین خط از عوامل (User-agent) و دستورالعمل ها باشد.
User-agent یا واسط کاربری که نوع خزنده را مشخص می کند (ربات های خزنده گوگل، یاهو، بینگ و …) و Disallow که شاما آدرس قسمتی است که دسترسی به آن را مسدود می کنیم. البته این فایل شامل دستور های دیگری هم می شود که در ادامه به آنها می پردازیم.
مثال 1: بلاک کردن تمامی موتورهای خزنده برای تمامی محتوای وب سایت.

ین دستور به تمامی موتورهای خزنده می گوید که این سایت را پیمایش نکنند.
مثال2: دسترسی آزاد برای تمامی موتور های خزنده.

این دستور به تمامی خزنده ها اجازه می دهد که کل محتوای سایت را پیمایش و ایندکس کنند.
مثال3: بلاک کردن یک موتور خزنده از یک بخش خاص از وب سایت.

.این دستور به موتور خزنده گوگل می گوید که محتویات پوشه example-subfolder را پیمایش نکند ولی اجازه پیمایش سایر فولدر ها را دارد.
مثال 4: بلاک کردن یک موتور خزنده از دسترسی به یک صفحه خاص از وب سایت.

این دستور به موتور خزنده Bing می گوید که از پیمایش و ایندکس کردن صفحه blocked-page.html خودداری کند.
نکات:
– نام فایل به حروف بزرگ و کوچک حساس می باشد. در نتیجه باید دقیقا robots.txt باشد نه Robots.txt یا robots.TXT یا هر چیز دیگری.
– فایل robots.txt به صورت در دسترس همگان قرار دارد. کافیست /robots.txt را به انتهای نام سایت اضافه کنید تا بتوانید دستورالعمل های وب سایت را مشاهده کنید.این بدان معنی است که هر فردی می تواند ببیند شما می خواهید چه پوشه هایی از وب سایت خود توسط ربات ها پیمایش نشود. پس از این قسمت برای مخفی کردن پوشه های مهم استفاده نکنید.
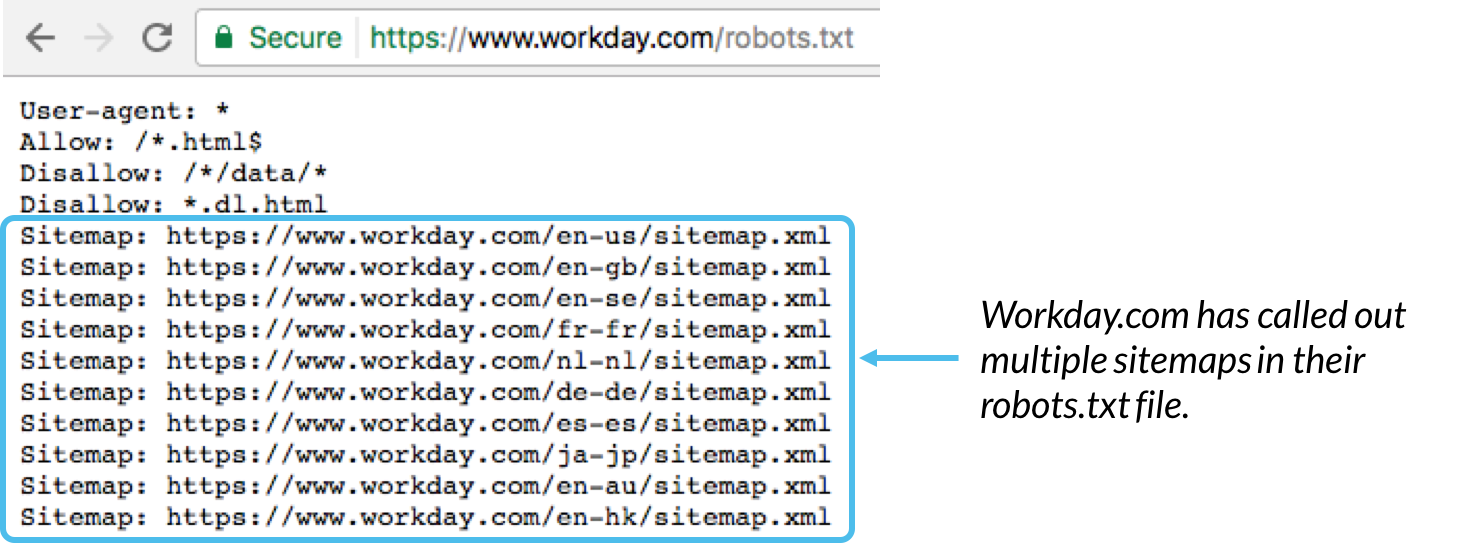
– به طور کلی بهترین روش برای نشان دادن مکان هر sitemap مربوط با دامین ما در پایین فایل robots.txt می باشد. به مثال زیر توجه کنید:
سینتکس فایل robots.txt :
در این قسمت به معرفی کامل دستور فایل robots.txt می پردازیم:
User-agent : نام ربات خزنده را مشخص می کند. مانند: Googlebot, Bingbot, msnbot, Slurp(yahoo bot)
Disallow : این دستور به ربات ها اعلام می کند که اجازه پیمایش این قسمت را ندارند.
Allow : این دستور فقط و فقط به ربات گوگل می گوید که اجازه دستری به یک زیر بخش از سایت را دارد حتی اگر دسترسی به بخش پدر غیر مجاز شده باشد.
Crawl-delay : مشخص می کند که چند میلی ثانیه یک ربات باید قبل از پیمایش و بررسی محتویات یک صفحه صبر کند. توجه داشته باشید که ربات گوگل به این دستور توجه نمی کند. شما می توانید این پارامتر را برای ربات گوگل از طریق Google Search Console تنظیم کنید.
Sitemap : این دستور برای مشخص کردن مکان تمام سایت مپ های یک دامنه به کار می رود. توجه کنید که این دستور را فقط google, Ask, Bing, Yahoo پشتیبانی می کنند.
 تیم تولید محتوا
تیم تولید محتوا